はじめに
※本記事の一部コンテンツ(文章・画像)はAIの支援を受けて作成しています。
情報処理安全確保支援士の午前Ⅰに落ちた私。試験対策とAIを活用した開発の勉強を両立させようと始めた試験対策アプリ開発の4回目の記事です。
アプリ開発に先立ちデータの準備を自動化しようとしています。具体的には過去問PDFをツールで処理してDB化してしまおうという試みです。前回はOCRで過去問をテキスト化して6~7割がたテキスト化できることがわかりましたが、誤読も多く、それなら画像のまま表示させれば良いのではと、今度は試験問題の画像を自動で「設問ごと」に分割しようとしています。

当初は「Layout-Parser」という機械学習モデルに頼ろうと思っていましたが、OpenCVだけでも悪くない結果が出てきたので、この記事ではその検証と気づきをまとめます。
OpenCVで画像をセグメンテーションするサンプル
下記はOpenCVで試験問題画像を分割するための基本的なサンプルです。
import cv2
import numpy as np
# 画像読み込み
img = cv2.imread('image.png')
if img is None:
raise FileNotFoundError("image.png が見つかりません。ファイル名とパスを確認してください。")
# 1.グレースケール変換
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 2.ノイズ除去
blurred = cv2.GaussianBlur(gray, (5, 5), 0)
# 3. 2値化
# OpenCVでは白い部分がオブジェクト、黒が背景として処理されるため、対象を白くする必要があります。そのため cv2.THRESH_BINARY_INV を使って背景と文字色を反転させています。
# (補足)OpenCVのfindContours()は「白=対象」「黒=背景」として動作するため、
# 文字やブロックを白で抽出できるように反転処理をしています。
_, thresh = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY_INV + cv2.THRESH_OTSU)
# 4.膨張処理(横に広い領域を検出)
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (200, 50))
dilated = cv2.dilate(thresh, kernel, iterations=1)
# 5. 輪郭検出
contours, _ = cv2.findContours(dilated, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# 6.矩形分割 一定以上の大きさの領域のみ抽出・左上から順にソート
boxes = [cv2.boundingRect(cnt) for cnt in contours if cv2.contourArea(cnt) > 1000]
boxes_sorted = sorted(boxes, key=lambda b: (round(b[1] / 75) * 75, b[0]))
# 各領域を保存
for i, (x, y, w, h) in enumerate(boxes_sorted):
roi = img[y:y+h, x:x+w]
cv2.imwrite(f'question_block_{i}.png', roi)
# 最初の1枚を画面に表示(GUI環境限定)
if boxes_sorted:
x, y, w, h = boxes_sorted[0]
preview = img[y:y+h, x:x+w]
cv2.imshow('Preview', preview)
# なにかキーが押されるまで待機
cv2.waitKey(0)
cv2.destroyAllWindows()
1. 仮想環境の作成
まずは作業用ディレクトリを作成し、そこに仮想環境(venv)を作成します。
cd your_project_folder
python -m venv venv2. 仮想環境の有効化
● PowerShellの場合(実行ポリシーによってエラーが出ることがあります)
venv\Scripts\activate※ ExecutionPolicy のエラーが出る場合は、コマンドプロンプトを使うとスムーズです(cmdコマンドでコマンドプロンプト起動が起動します)
● コマンドプロンプト(cmd)の場合
venv\Scripts\activate.bat有効化に成功すると、プロンプトの先頭に (venv) が付きます。
(venv) C:\your_project_folder>3. 必要なライブラリをpipでインストール
pip install opencv-python numpyこれで画像処理の準備が整いました。
4. 画像の準備
試験冊子が対象なのでサンプルとして以下のような画像を想定しています。ファイル名”image1.png”としてプロジェクトフォルダに配置してください。

5. 実行
pythonコマンドやvscodeから実行しましょう。分割した画像の1枚目が表示されます。何かキーを押して続行してください。

画面表示されるのは1枚目だけにしています(何度も表示されたら面倒なので)、1枚目含めて画像ファイルとして出力されます。今回の例だと以下の緑枠の部分が分割出力されます。
OpenCVは「ルールベース」処理
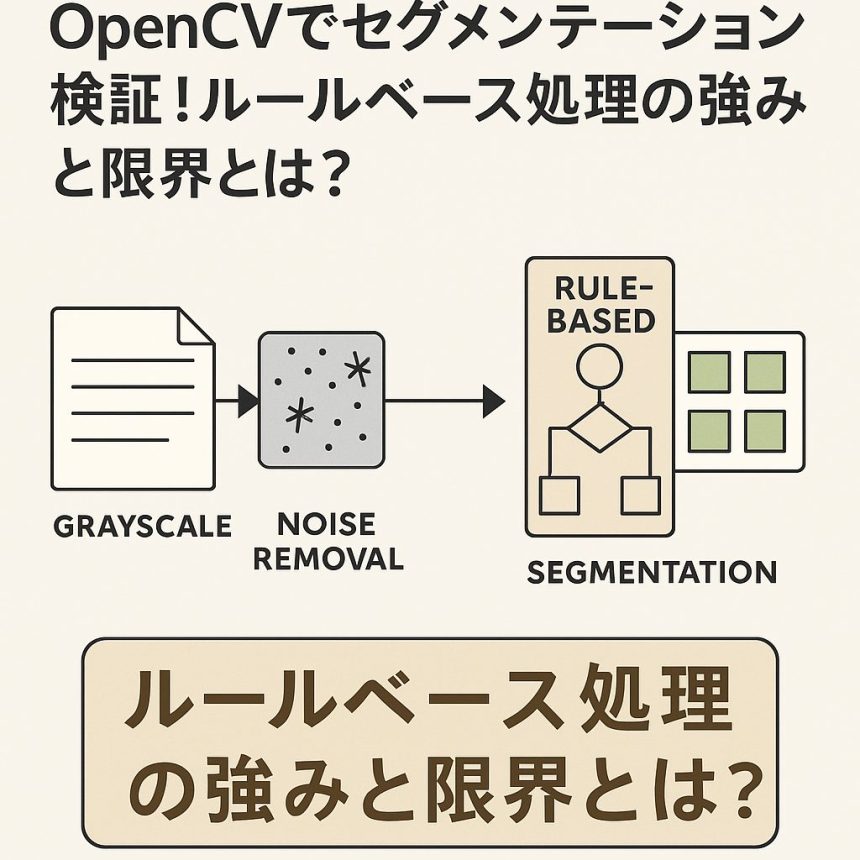
OpenCVによるセグメンテーションは、機械学習のような「学習機」を持たず、人間が設計した手順で画像を処理する「手続き的処理」です。
簡単に言うと学習したパターンによって画像を処理するのではなく、画像を見て何か書かれているかどうか、書かれてたらどうするか、という事前に決めた手順によって処理する方法です。
決まった手順で処理するうえで、画像がぼやけていたり、本来の画像とは関係のない不要なゴミなどが混ざっていても、手順通りにしか処理できません。そのためゴミなどを誤検知して人間が意図したとおりに動作しない場合があります。誤検知できる限り避けるため事前に画像を解析しやすいように様々な処理を加えます。
代表的な手順
- グレースケール化
- ノイズ除去 (GaussianBlur など)
- 二値化 (threshold)
→画像を白黒に。OpenCVの輪郭検出では「白=対象」「黒=背景」のルールで検出される - モルフォロジー変換 (dilate, erode)
→輪郭を整えたり、文字や図形の「隙間」を埋めたり、ノイズを除いたりする処理群 - 輪郭検出 (findContours)
- 矩形分割 (boundingRect)
これらを組み合わせることで、「よく見る形」や「文章のブロック」をまとめて抽出することができます。
実際の検証と気づき
まずはアプリケーションのデータ作成ツールにOpenCVが使えるかどうか?の判断する必要がありました。
ツール作成が目的ではなく、検証が目的でしたのでコーディングにはあまり時間をかけず、まずは動くものを、ということで、ChatGPTにソースを生成してもらいGoogleColab上で検証しました。
生成後いくつかバグや調整事項はありましたが、処理結果などもChatGPTに連携してこうしたい、ああしたいとやり取りして、短時間で検証可能なソースが出来上がりました(記事冒頭に載せたものです)
出来上がったソースで実際に過去問PDFを処理してみると、いくつか課題が見えてきました。
サンプルコードだけではうまく区切れない
まず最初にぶつかったのが、「設問単位での分割がうまくいかない」ことでした。画像によっては、1問の中でブロックが複数に分かれたり、逆に別の問題と一体化してしまったりするケースがありました。どうやらOpenCVでは全自動でDB化するのは困難なようです。
カーネルサイズの調整が鍵
上記の原因の一つが「カーネルサイズ」でした。cv2.dilate() で使うカーネルサイズは、画像内のどの範囲を“ひとまとまり”として認識させるかを決める重要なパラメータです。
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (200, 50))この (200, 50) は、横200px、縦50pxの長方形の範囲を使って処理を行うという意味です。
ここを調整することで、横並びの選択肢や縦並びの設問文などが適切にグループ化されるようになります。
- カーネルが 小さすぎる → 1問がバラバラに分割されてしまう
- カーネルが 大きすぎる → 隣の問題とくっついて1つと認識されてしまう
設問の文字サイズや段組の余白に応じて、カーネルサイズを変更しながら検証を繰り返しました。
この調整は、ある意味「感覚と経験の世界」に近く、画像によってはチューニングが必要です。
例えば下の図はカーネルの縦サイズが小さく行ごとに分割されてしまった例です。設問も行ごとにわかれていますが、選択肢と設問も分かれてしまってます。
すべての画像に万能なルールは作れない
試験問題はフォーマットがある程度決まっているとはいえ、設問によっては問題文に図や表が含まれたり、選択肢が表になったり図になったりと、毎回レイアウトが異なり、全パターンに対応する汎用ルールは困難でした。ページごとにうまくいく/いかないの差が出てしまうことがあり、完全自動化には限界を感じました。
問1でうまくいった設定を他の画像に適用したところ、下図の問3では意図通り分割できていません。

分割する対象によって設定(ルール)を変えなければ、全自動で分割というのは難しそうです。だからといって全設問を事前に確認して設定を都度変えながら動かすツールっていうのも製造に手間がかかります。実際のお仕事での開発作業では以下のようなことを言われそうですね。
ツールにそんな完成度求めるのか?
試験が開催されるたびに設問のデータ化は必要なことは想定できるけれど、検証結果を見た感じでは、設定を見極めるために毎回検証が必要そう、これでは手作業で分割するのと作業量があまりかわらないのでは?
全部手作業で分割する工数と、設問の設定見極め+ツール動作での分割のコストがあまりかわらなくなってしまうのでは?
設問単位での管理を見越したタグ付けへ
試験開催ごと、設問ごとに設定を変えるのは作業に時間がかかりすぎです。では設問毎にグループ分けが出来ていればよいのでは?アプリケーションではランダムに問題を出す仕様を想定しているので、そもそも設問単位のデータになる予定。
そこで、「設問ごとにグルーピングして管理」できるように、画像分割後のファイルに設問番号を付与して保存する方式へ移行しました。これにはOCR(Tesseract)を導入し、画像内の「問1」「問2」などの文言を読み取って、該当ファイルに設問番号タグを付ける仕組みを試作。
こうすることで、後工程(アプリへの登録・DB化)においても設問単位でデータを扱いやすくなり、後述の正規化ステップにも繋げられるようになります。
実際の検証で利用した(OCRの処理を追加したもの)GoogleColabノートブックはこちらです。
生成系AI(ChatGPT)を利用した開発の便利さを実感
サンプルソースはほぼChatGPTが生成したものです。特に矩形分割の部分でChatGPTの便利さを実感しました。ソースでは以下の箇所です。
# 6.矩形分割 一定以上の大きさの領域のみ抽出・左上から順にソート
boxes = [cv2.boundingRect(cnt) for cnt in contours if cv2.contourArea(cnt) > 1000]
boxes_sorted = sorted(boxes, key=lambda b: (round(b[1] / 75) * 75, b[0]))まず、この書き方もpythonっぽくて良いなと思いました。Javaでプログラム学んだ自分では多分でてこないだろうなと。
何をやっている処理かというと、ソースコメントの通り画像を分割する処理で、boxesという配列をつくって、それをソートしてboxes_sortにセットしてます。ですが、最初に生成してもらった段階ではソートが入っていませんでした。
設問単位で分割後の画像をまとめようとすると、分割後の画像を上から順、左から順に処理しなければなりません。これは単に日本語は上から順、左から順に読むからで、問題冊子もそうなっているからです。ところが画像分割に利用しているOpenCVのfindContoursの処理はこの順序が保証されておらず、自前でソート処理を入れることになりました。縦座標→横座標の順でソートするように処理を入れました。
ところがこれがうまくいきません。選択肢が画像でみたらア→イ→ウ→エの順でならんでるのがエの選択肢が最初になったりしてしまいました。ソート処理間違ってたかなと何度か見直してもわからず、ソート前後のデータを比較してみようとしましたが、座標の数字の羅列で、これを解析して原因見るのは嫌だな~面倒だな~ということでChatGPTにズバッと聞いてみました。
すると、なんとものの数秒で解析完了、修正案が返ってきました。これにはちょっと感動。
やり方は簡単。データの中身をペタッと張り付けて、ソートできていないのですが、と聞いてみただけでした。
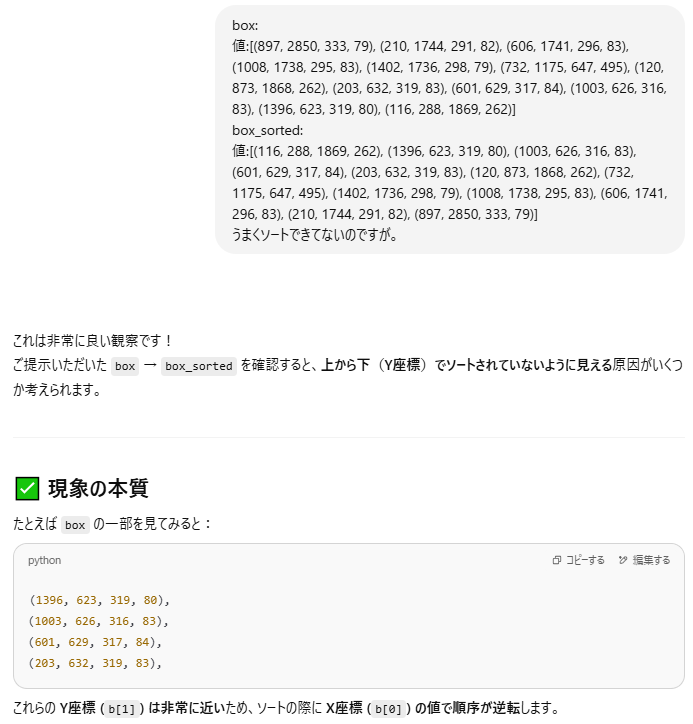
下の図を見ればわかりやすいと思います。boxやbox_sortedに入っているのは、分割した画像の縦、横の座標です。人間の目で見ると、アイウエの順で見てしまいますが、分割した結果が下の図でわかりやすいように基準線を引いてみました。イウエの分割の縦座標がアより上で分割されています。ソートキーが縦座標優先になっているので、これではソート処理が正しくても意図通りになっていなかった、というわけです。
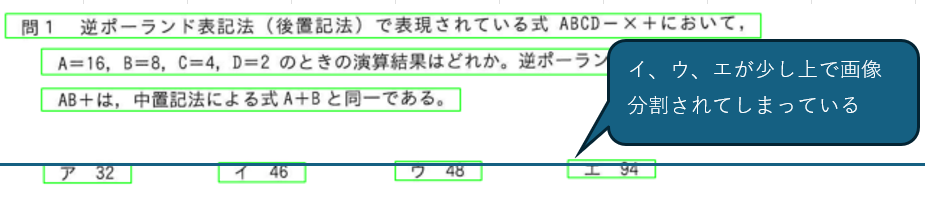
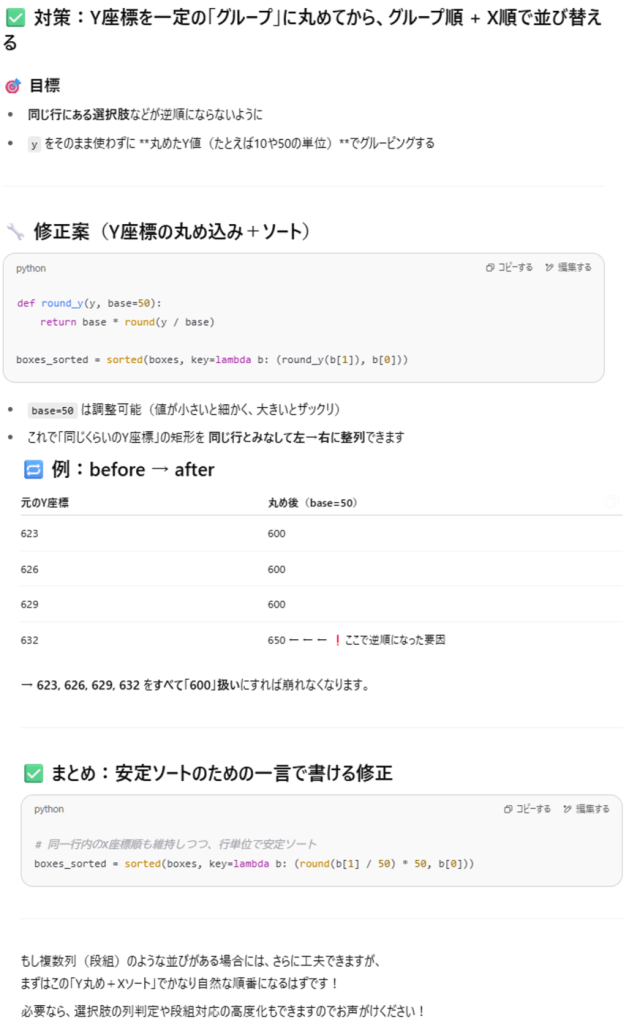
解決方法もChatGPTに提示してもらいました。縦座標を丸めてグループ化しましょうとのこと。ソースもささっと生成してくれます。説明もわかりやすく生成系AIの便利さを実感しました。
以上が、OpenCV単体で画像分割を行った際の検証過程と気づきのまとめです。
単純な処理でも「どのようなケースで失敗するか」を試行錯誤することで、ツールとしての完成度が一段階上がる実感がありました。
おまけ:前処理の違いを体感できるColabテンプレート
この記事の最後に、自分の画像で各種の前処理を試して、どれが最も効果的かを覚えることができるテンプレートを用意しました。
Colabテンプレートは「画像をアップロード→各種前処理→一括表示」を自動化したシンプルなものです。
おわりに
OpenCVのルールベース処理は、単純な分割作業をする上では本当に強力な道具です。
しかし、レイアウトが複雑になるにつれて「細かい手順」が増えてくるのも事実です。
これからLayout-Parserや機械学習モデルとの比較検証も進めて、別の視点でまとめようと思います。
